网站的基础SEO分析是对网站的营销价值做初步判断,以及从技术角度对网站各项Web指标进行检查诊断,就好比医生给病人看病一…
网站robots.txt文件的两种不同写法
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,robots默认都是放在网站根目录,但这只是默认的情况,还有其他方法,我们今天看一下两种配置方法。
Robots.txt案例
什么是Robots.txt文件,先看一下一个taobao的案例:
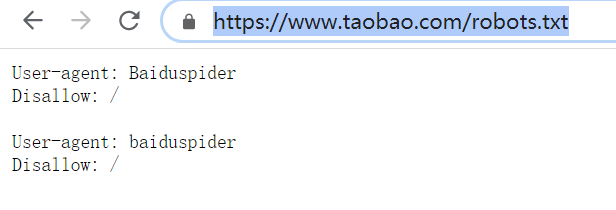
这是淘宝的爬虫策略,默认情况下如果不写,那么就是默认的都可以抓取,如果写了,就根据robots.txt文件执行,那么我们可以看到,taobao是不让百度爬虫抓取的,看一下site命令的效果:
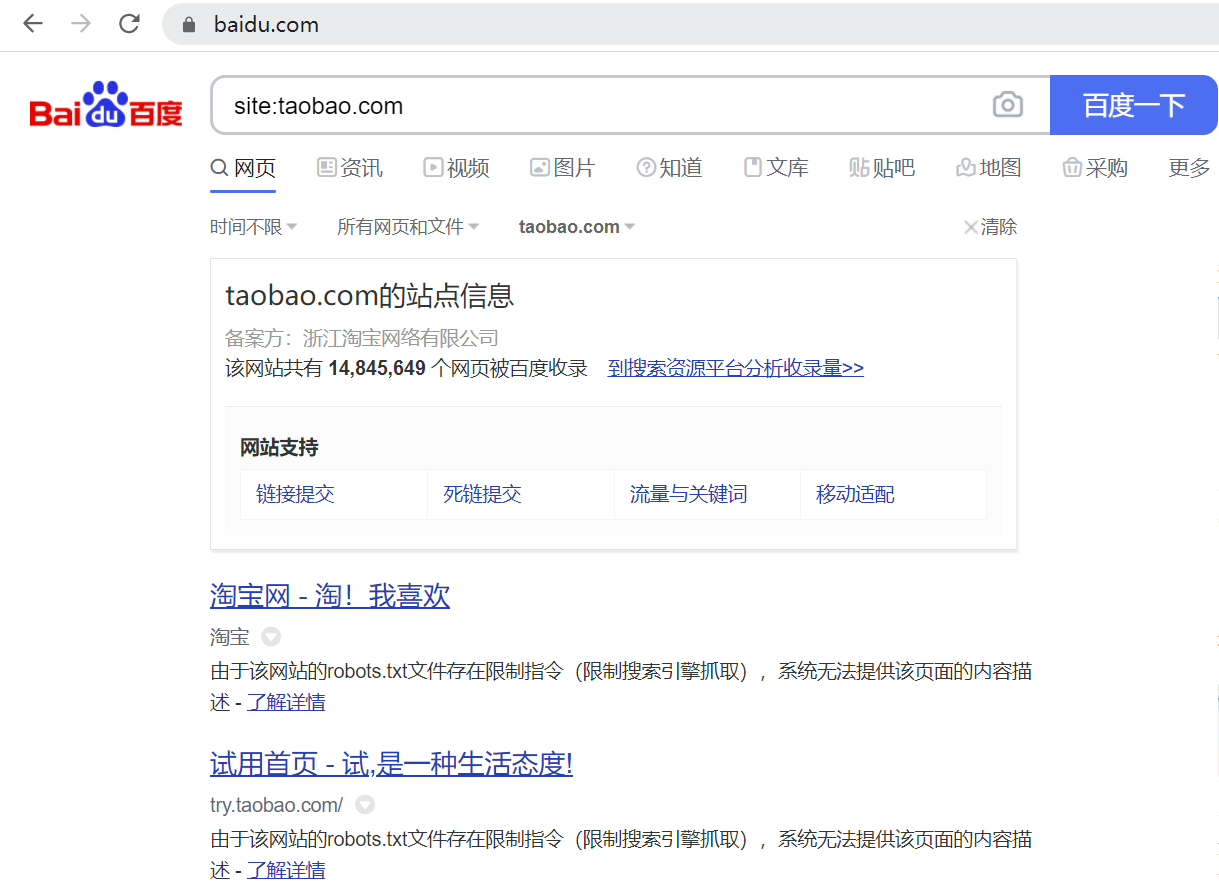
我们看淘宝对百度的态度,和百度对淘宝的态度。
淘宝不想让百度搜索,不想让百度成为淘宝的入口,因为如果这样,淘宝想做生意就被百度在前面拦截流量,需要付费了。当然,马云和李彦宏的分歧早就在某大会上公开表达过,所以,阿里收购了神马搜索,一个移动端的小的浏览器和能力比较弱的搜索引擎。
百度对淘宝的态度呢,我认为是这样的:你不让我搜索截流量,好的没问题,不让我们抓我们不能不抓,不懂的人以为我们没有能力,所以,我们必须得抓,而且要狠狠的抓,把页面都抓过来,然后显示你不让我抓。
我们观众怎么想呢,规则就是规则,有规则就有潜规则,在竞争中规则和潜规则的中间表达即为上图。如果想成为一个入口级的网站,一定要有一个好的域名支撑,如果决定了不是入口级别的网站,那么,就由搜索引擎优化影响你的命运吧。
robots.txt文件在根目录
robots.txt的文件制作很简单的,只需要把txt文件命名为robots,然后在文件中写好爬虫如何根据我们的机器人规则robots.txt进行执行爬取网页。
三个命令:
User-agent:
Disallow:
Allow:
写法:
命令+空格+内容+回车
如:
User-agent: *
*的意思是所有的爬虫,查看更多爬虫命名
但是还没有完,你允许蜘蛛爬虫爬你哪,不爬你哪需要说明,不说明默认都可以爬,其实我们只需要说明哪不让爬就是了,或者不让爬的文件夹中那个比较特殊让爬,再释放出来即可,让爬还是不让爬,因为robots.txt,最终是根据先后顺序进行的逻辑判断,先写的就是先计入逻辑,后写的后计入逻辑,一步步的去理解你的语义即为你的robots的意思。
完整的一个:
User-agent: *
Disallow: /
这个说明禁止所有的爬虫访问你的根目录,而如果没有“/”根目录符号却是完全相反的意思;
User-agent: *
Disallow:
这个空说明没有禁止,网站与爬虫弘扬传统友好没有止境,拓展合作没有禁区。
User-agent: *
Disallow: /
Allow: /mgshseo/*
这个说明不允许爬虫访问根目录,但除了/msghseo/*目录及其下面的所有子目录之外;
如果去掉“*”号,
User-agent: *
Disallow: /
Allow: /mgshseo/
表达的意思是不允许爬虫访问根目录,但是除了/mgshseo/文件夹之外,子文件夹也是不允许访问的。
如果只不允许百度爬虫,
User-agent: baiduspider
Disallow: /
即taobao之作。
用代码程序写Robots.txt
刚建好的WordPress网站,打开robots.txt是能访问的,但是在网站目录却找不到任何robots.txt文件,其实默认的robots文件放在wp-includes/functions.php中,通过搜索robots大概在1319行可进行修改:
本站使用的不是默认的Wordpress,已经修改了functions函数,无法截图,请自己查看。
更多阅读:
SEO基础知识-站长操作入门
中国品牌日有哪些内在的涵义?
SEO供应商如何提高客户品牌价值?
