网站的基础SEO分析是对网站的营销价值做初步判断,以及从技术角度对网站各项Web指标进行检查诊断,就好比医生给病人看病一…
搜索引擎蜘蛛篇-网络爬虫如何工作?
SEOer做网站优化时经常分析网站蜘蛛,网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
搜索引擎蜘蛛(spider)
网页的收录排名是离不开蜘蛛的,蜘蛛其实就是一个爬行程序可以通过网站的URL地址抓取网站信息。
- 1、百度蜘蛛:Baiduspider
- 2、谷歌蜘蛛:Googlebot
- 3、360蜘蛛:360Spider
- 4、SOSO蜘蛛:Sosospider
- 5、雅虎蜘蛛:“Yahoo! Slurp China”或者Yahoo!
- 6、有道蜘蛛:YoudaoBot,YodaoBot
- 7、搜狗蜘蛛:Sogou News Spider、Sogou XXX spider等
- 8、MSN蜘蛛:msnbot,msnbot-media
- 9、必应蜘蛛:bingbot
- 10、一搜蜘蛛:YisouSpider
- 11、Alexa蜘蛛:ia_archiver
- 12、宜sou蜘蛛:EasouSpider
- 13、即刻蜘蛛:JikeSpider
- 14、一淘网蜘蛛:EtaoSpider
- 15、今日头条蜘蛛:Bytespider
这些据说是国外蜘蛛YandexBot、AhrefsBot和ezooms.bot
网络爬虫的案例
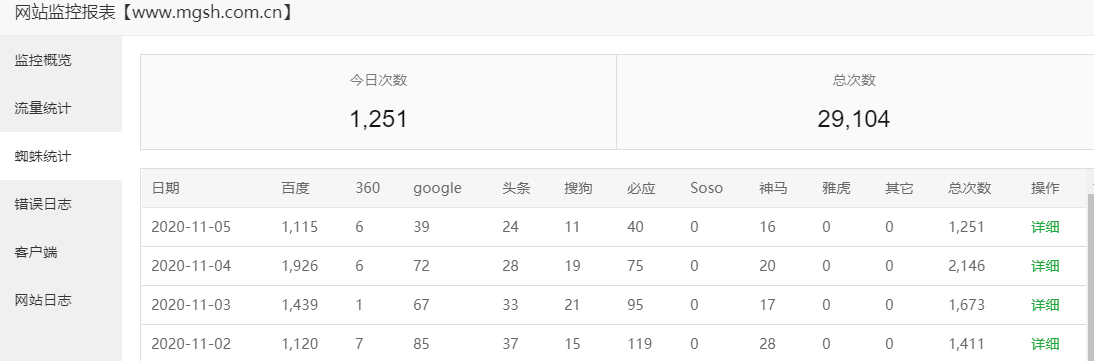
我们看看搜索引擎的对比:
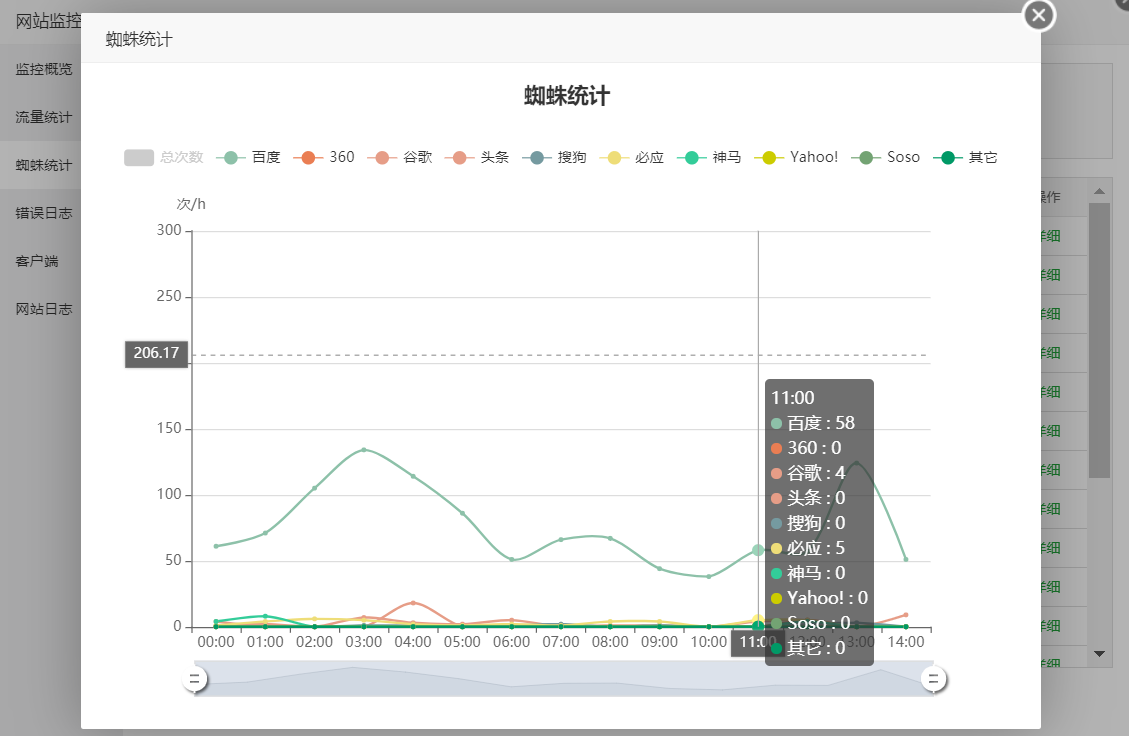
最高的的是百度,搜索引擎或者浏览器的市场不管怎么吹嘘比例,都无法否认百度蜘蛛/服务器的勤劳,以及其发挥的我国搜索引擎的作用,别人是干不动的。
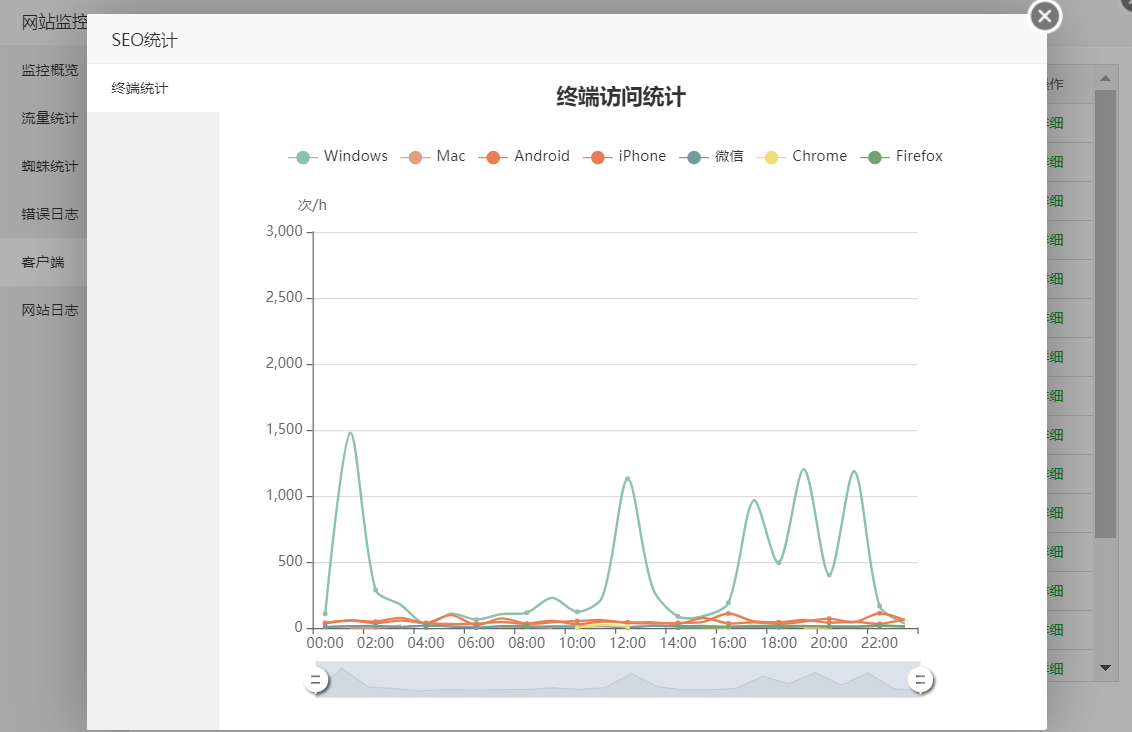
访问网站的终端还是windows最多,使用windows的用户通过PC端访问,toB业务还是要依托电脑。
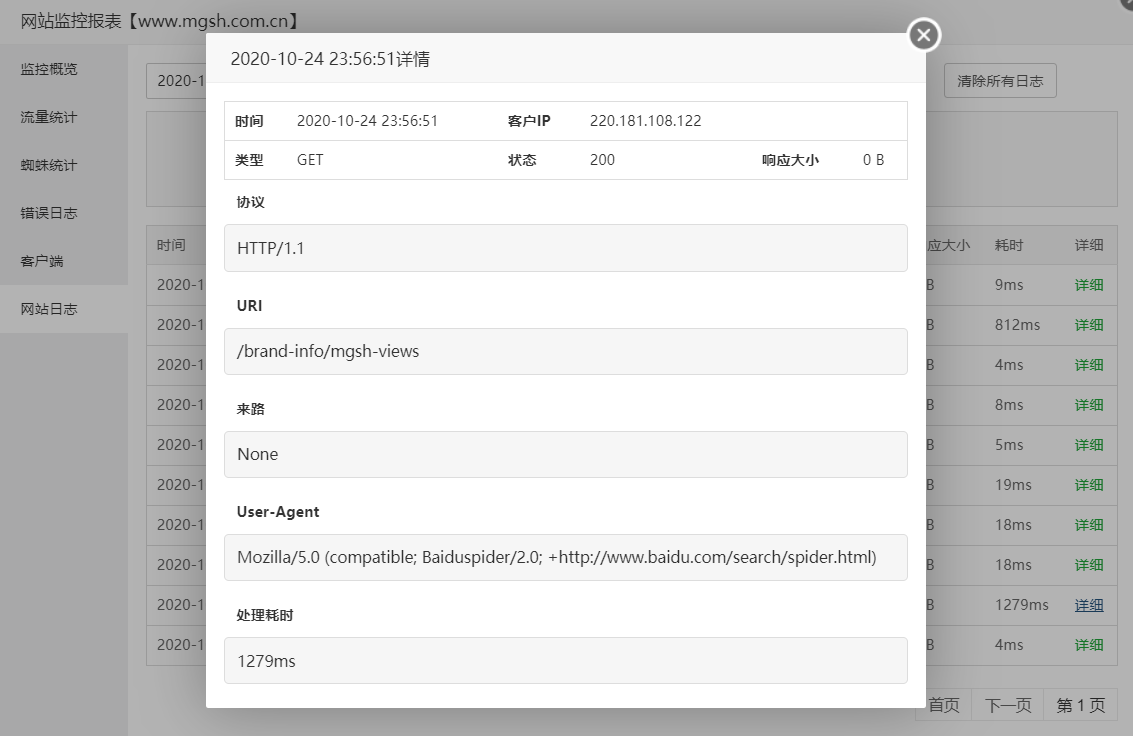
百度蜘蛛,Baiduspider在User-Agent的样子,如上图,如果User-agent的值为None或者其他浏览器,而没有搜索引擎,那可能是人-用户的访问,而不是机器-蜘蛛的访问。
robots协议
蜘蛛进入网站最先抓取的文件,可以控制蜘蛛抓取的网站内容,当然,有的蜘蛛不遵守蜘蛛的规则,你拒绝它访问,它还是能访问的,因为这个规则没有被写入法律,法律在技术层面还相当跟不上。
User-Agent: *
Disallow: /
这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以”.htm”为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址 Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片 Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。 Allow: .gif$ 允许抓取网页和gif格式图片 Sitemap: 网站地图 告诉爬虫这个页面是网站地图
robots的使用说明延伸阅读:
robots使用方法
五分钟SEO入门指南
